https://studiolettuce.tistory.com/48
[Kaggle/캐글]타이타닉 생존률 분석_1
Kaggle 하면 거의 모든 분들이 거쳐간다고 할 수 있는 타이타닉 생존 분석을 진행해봤습니다. 간단하게는 결측치를 모두 날려버리고 단순하게 의사결정나무를 적용해서 분석을 할 수 있지만 되도
studiolettuce.tistory.com
이어서 쓰는 두 번째 글입니다.
일전에 결측치를 채우는 방법에서 했던 실수를 다시 작업하였습니다.
결측치를 채운 방법은 이전과 동일한 형태로 작업하였습니다.
결측이 없는 데이터를 re_age 테이블을 만든 뒤 해당 테이블의 히스토그램을 불러옵니다.
import matplotlib.pyplot as plt
re_age = df[(df.Pclass == 3) & (df.SibSp == 0) & (df.Parch == 0) & (df.Sex == 1) & (df.Age != 0)]
#re_age.head
plt.hist(re_age.Age)
plt.show() #현재 3등실의 가족 없는 남자의 연령별 히스토그램
그리고 결측이 발생한 위치에 age_test에서 랜덤 추출한 값을 넣어주는 방식으로 히스토그램의 형태가 가장 유사하게 나올 수 있도록 반복하였습니다.
for i, row in df.iterrows() :
if df.at[i,'Pclass'] == 3 and df.at[i,'Sex'] == 1 and df.at[i,'SibSp'] == 0 and df.at[i,'Parch'] == 0 and df.at[i,'Age'] == 0 :
df.at[i,'age_test'] = re_age.Age.iloc[np.random.randint(1,len(re_age.Age))]
plt.hist(df[(df.Pclass == 3) & (df.SibSp == 0) & (df.Parch == 0) & (df.Sex == 1)].age_test)
plt.show() #Age가 누락된 인원들의 데이터를 표본추출로 대입한 후의 히스토그램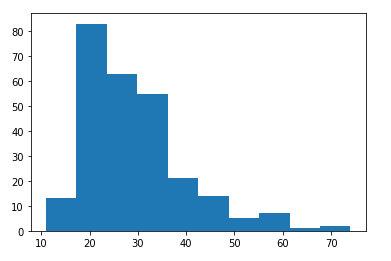
그렇게 만들어진 결측치가 채워진 데이터를 다시 각 빈 공간에 대입해서 히스토그램을 완성합니다.
for i, row in df.iterrows() :
if df.at[i,'Pclass'] == 3 and df.at[i,'Sex'] == 1 and df.at[i,'SibSp'] == 0 and df.at[i,'Parch'] == 0 and df.at[i,'Age'] == 0 :
df.at[i,'Age'] = df.at[i,'age_test']
plt.hist(df[(df.Pclass == 3) & (df.SibSp == 0) & (df.Parch == 0) & (df.Sex == 1)].Age)
plt.show() #Age가 누락된 인원들의 데이터를 표본추출로 대입한 후의 히스토그램
이런 방식으로 성별 / 3등실, 2등실, 1등실 / 가족 유무로 총 8번의 반복으로 결측치를 모두 채웠습니다.
Age칼럼은 모두 0으로 채워져 있기 때문에 isnull로 검증이 어려워 value_counts로 값을 불러왔습니다.
df['Age'].value_counts()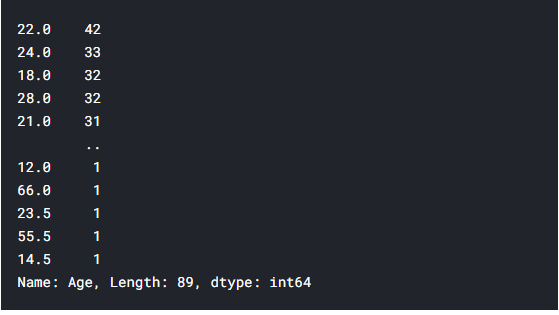
모든 결측치를 채운 후 각 항목들 간의 상관관계를 추출하여 항목들간의 유의미한 영향도를 가지는지 확인하였습니다.
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import plot_tree
plt.figure(figsize=(10,10))
sns.heatmap(df.corr(),cmap='coolwarm',annot=True)
plt.show()상관분석에서는 성별과 생존율이 음의 상관관계가 강한 것으로 보입니다.
이는 성별이 0일 때 여성, 생존율은 1일 때 생존이다 보니 그만큼 여성의 생존율이 높다는 것을 바로 확인할 수 있습니다.
Parch와 SibSp는 가족의 유무다 보니 당연히 부모가 있는 인원이 있으면 자식이 있는 인원이 있기 때문에 양의 상관관계를 가질 수 있습니다.

이 데이터를 우선 의사결정 나무로 먼저 돌렸습니다.
깊이는 3단계까지로 해서 범위에 제한을 뒀습니다.
x = df.drop(['Survived'], axis=1)
y = df['Survived']
xname = x.columns
yname = ['Death', 'Survived']
c_tree = DecisionTreeClassifier(max_depth=3,random_state=0)
c_tree.fit(x, y)
plt.figure(figsize=(50,10))
plot_tree(c_tree, feature_names=xname, class_names=yname, filled=True, fontsize=12)
plt.show()
이제 테스트 값을 가져와서 데이터를 채웁니다.
df1 = pd.read_csv('/kaggle/input/titanic/test.csv')
df1 = df1.drop(["PassengerId","Name","Cabin","Fare","Ticket","Embarked"], axis=1)
df1['Sex'] = df1['Sex'].replace({'male':1, 'female':0})
df1.insert(0,'Survived',np.NaN)
df1.head(20)테스트 데이터에는 Survived가 없기 때문에 해당 테이블을 가장 앞으로 가져오고 np.NaN을 통해서 NaN값을 넣습니다.

이제 Age 테이블에 결측치가 있는지 확인하기 위해서 isnull을 사용하였습니다.
df1.isnull().sum()해당 테이블에도 Age에 결측치가 있는 것을 확인하여 동일한 방법으로 히스토그램을 이용하여 결측치를 채워줍니다.

결측치 채우는 방법은 위에서 사용했던 히스토그램을 비교해서 유사한 형태로 채워주는 방식이라 별도로 설명을 하진 않겠습니다.
신규 테이블 생성 및 NaN값을 0으로 변환
df1.Age = df1.Age.fillna(0)
df1['age_test'] = df1['Age']
df1.age_test = df1.age_test.fillna(0)
df1.headre_age = df1[(df1.Pclass == 3) & (df1.SibSp == 0) & (df1.Parch == 0) & (df1.Sex == 1) & (df1.Age != 0)]
#re_age.head
plt.hist(re_age.Age)
plt.show() #현재 3등실의 가족 없는 남자의 연령별 히스토그램
for i, row in df1.iterrows() :
if df1.at[i,'Pclass'] == 3 and df1.at[i,'Sex'] == 1 and df1.at[i,'SibSp'] == 0 and df1.at[i,'Parch'] == 0 and df1.at[i,'Age'] == 0 :
df1.at[i,'age_test'] = re_age.Age.iloc[np.random.randint(1,len(re_age.Age))]
plt.hist(df1[(df1.Pclass == 3) & (df1.SibSp == 0) & (df1.Parch == 0) & (df1.Sex == 1)].age_test)
plt.show() #Age가 누락된 인원들의 데이터를 표본추출로 대입한 후의 히스토그램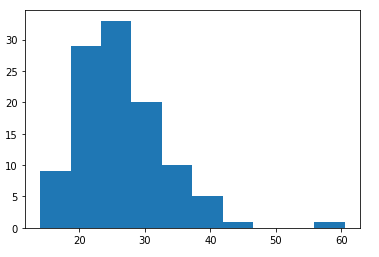
for i, row in df1.iterrows() :
if df1.at[i,'Pclass'] == 3 and df1.at[i,'Sex'] == 1 and df1.at[i,'SibSp'] == 0 and df1.at[i,'Parch'] == 0 and df1.at[i,'Age'] == 0 :
df1.at[i,'Age'] = df1.at[i,'age_test']
plt.hist(df1[(df1.Pclass == 3) & (df1.SibSp == 0) & (df1.Parch == 0) & (df1.Sex == 1)].Age)
plt.show() #Age가 누락된 인원들의 데이터를 표본추출로 대입한 후의 히스토그램

위의 방식으로 결측 된 데이터를 모두 채웠습니다.
그럼 여기부터는 머신러닝을 통한 데이터 분석을 진행하도록 하겠습니다.
x, y값에 분석 데이터를 넣어주고, x_1과 y_1에 테스트 데이터를 넣어줬습니다.
x = df.drop(['Survived'], axis=1)
y = df['Survived']
x_1 = df1.drop(["Survived"], axis=1)
y_1 = df1['Survived']
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.4, random_state=0, stratify=y)첫 번째 방식은 로지스틱스 회귀분석입니다.
Sklearn 안에서 LogisticRegression을 불러와서 작업할 수 있습니다.
그렇게 테스트 데이터를 적합시키고 roc curve를 불러왔습니다.
from sklearn.linear_model import LogisticRegression
m1 = LogisticRegression(random_state=0, max_iter = 1000)
m1.fit(x_train, y_train)
m1_prob = m1.predict_proba(x_test)
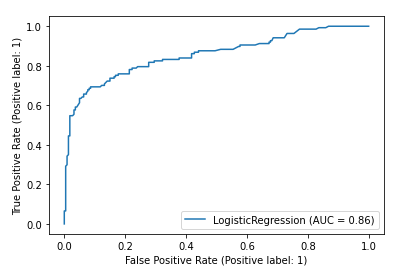
from sklearn.metrics import plot_roc_curve
m1_roc=plot_roc_curve(m1, x_test, y_test)AUC가 0.86 수준이면 꽤 준수하게 나오고 있습니다.
그럼 추가로 의사결정나무를 사용하겠습니다.
from sklearn.tree import DecisionTreeClassifier
m2 = DecisionTreeClassifier(ccp_alpha=0.0,min_impurity_decrease=0.0005,min_samples_split=2,random_state=0)
m2.fit(x_train, y_train)from sklearn.metrics import plot_roc_curve
m1_roc=plot_roc_curve(m1, x_test, y_test)
plot_roc_curve(m2, x_test, y_test, ax = m1_roc.ax_)
plt.title("ROC curve comparison")
plt.show()의사결정 나무는 AUC가 0.75로 생각보다 조금 낮은 편입니다.

바로 연달아서 신경망 분석을 사용했습니다.
숨김 레이어는 5개 수준으로 작업하였습니다.
from sklearn.preprocessing import StandardScaler
from sklearn.neural_network import MLPClassifier
scaler = StandardScaler()
x_train_scaled = scaler.fit_transform(x_train)
x_test_scaled = scaler.transform(x_test)
c_nn = MLPClassifier(hidden_layer_sizes=(5),random_state=0, max_iter = 1000)
c_nn.fit(x_train_scaled, y_train)또한 SVM 분석 역시 같이 진행하였습니다.
from sklearn import svm
c_svm = svm.SVC(kernel='rbf', random_state=0)
c_svm.fit(x_train_scaled,y_train)마지막으로 랜덤 포레스트 기법을 사용하여 모든 데이터를 트레이닝하였습니다.
from sklearn.ensemble import RandomForestClassifier
c_rf = RandomForestClassifier(random_state=0)
c_rf.fit(x_train,y_train)이에 대한 ROC 커브를 모두 추출하였습니다.
m1_roc=plot_roc_curve(m1, x_test, y_test)
plot_roc_curve(m2, x_test, y_test, ax = m1_roc.ax_)
plot_roc_curve(c_nn, x_test_scaled, y_test, ax = m1_roc.ax_)
plot_roc_curve(c_svm, x_test_scaled, y_test, ax = m1_roc.ax_)
plot_roc_curve(c_rf, x_test, y_test, ax = m1_roc.ax_)
plt.title("ROC curve comparison")
plt.show()로지스틱스 회귀분석이 0.86으로 가장 적합도가 높은 것으로 나왔기 때문에 이를 그대로 반영하였습니다.

로지스틱스 회귀분석의 테이블이 m1 테이블로 모델링하였기 때문에 해당 테이블을 불러옵니다.
predict_2 = m1.predict(x_1)
reslut = pd.read_csv('/kaggle/input/titanic/gender_submission.csv')
reslut.Survived = predict_2
reslut.to_csv('reslut.csv', index=False)이런 식으로 Survived에 Age 데이터를 붙여 넣습니다.
이를 캐글에 제출합니다.
제출은 저도 조금 헤매었습니다.
노트를 저장한 뒤 Edit 옆의 점 3개를 눌러서 Submit to Competition을 해주시면 됩니다.
로지스틱스 회귀분석으로 적합을 진행하였지만 예측률은 76.5% 수준이었네요.
전체 41,598개의 팀 중 32,834등이니.... 상위 79%.. 내요
차후에 90% 정도까지는 적합할 수 있도록 개선점을 더 찾아봐야 할 것 같습니다.

코드는 아래와 같습니다.
다만 스스로 테스트를 해보던 코드들도 남아 있어 굉장히 코드가 지저분합니다.
https://www.kaggle.com/jinhyunkwon/logisticregression
LogisticRegression
Explore and run machine learning code with Kaggle Notebooks | Using data from Titanic - Machine Learning from Disaster
www.kaggle.com
'데이터 분석 > 파이썬' 카테고리의 다른 글
| [Kaggle/캐글]PUBG 승률예측_1 (0) | 2021.05.31 |
|---|---|
| [Kaggle/캐글]타이타닉 생존률 분석_1 (0) | 2021.05.24 |
| [Kaggle/캐글]롤(lol) 챌린저 리그 오브젝트 영향 분석_1 (2) | 2021.05.18 |