Kaggle 하면 거의 모든 분들이 거쳐간다고 할 수 있는 타이타닉 생존 분석을 진행해봤습니다.
간단하게는 결측치를 모두 날려버리고 단순하게 의사결정나무를 적용해서 분석을 할 수 있지만
되도록이면 결측치를 채우는 방법을 사용하였기 때문에 삽질과 실수가 많음을 이해 바랍니다.
결과적으로 첫번째 게시글은 실패에 대한 글입니다.
아직 데이터를 업로드 하지 않았기 때문에 코드에 대한 내용은 이곳에만 적도록 하겠습니다.
게다가 이곳에 쓰인 코드는 실제 데이터 분석에는 쓰이지 않을 것 같습니다.
가장 기본적인 코드인 데이터를 불러오는 코드입니다. 별도 설명은 하지 않도록 하겠습니다.
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session실행하게 되면 아래와 같이 나오게 되고, 사용할 csv파일들의 경로가 나오게 됩니다.
gender_submission.csv는 간단하게 성별로만 분류된 결과 데이터입니다.

먼저 train 데이터를 불러와서 필요 없는 데이터를 제거해줍니다.
제가 생각한 분류의 범위는 일반적으로 생각할 수 있는 감정적 요인이 실제 적용되었는가에 대해서 생각해봤습니다.
죽을 위기에 처한 상황에서 누군가 말하는 자식이 있다는 말 혹은 자식을 위해서 자신은 살아야 한다는 말을 듣게 되면 감정적으로 구조정을 양보할 수도 있고 또한 타이타닉이 침몰하던 그 시기에는 아이와 여자를 먼저 지켜야 한다는 말이나 신념이 많았던 것을 생각해보면 자식과 부모에 대한 데이터인 SibSp와 Parch는 주요한 데이터로 쓰일 것으로 판단했습니다.
그럼 이런 부분에 맞춰 의미가 없는 PassengerId, Name, Cabin, Fare, Ticket을 삭제하고
문자열로 표기되어 있는 Embarked와 Sex를 replace 하여 숫자 값으로 변경하였습니다.
그리고 상위 10개의 데이터를 불러와 정상 적용되었는지 확인하였습니다.
df = pd.read_csv('/kaggle/input/titanic/train.csv')
df = df.drop(["PassengerId","Name","Cabin","Fare","Ticket"], axis=1)
df['Embarked'] = df['Embarked'].replace({'S':1, 'Q':2, 'C':3})
df['Sex'] = df['Sex'].replace({'male':1, 'female':0})
df.head(10)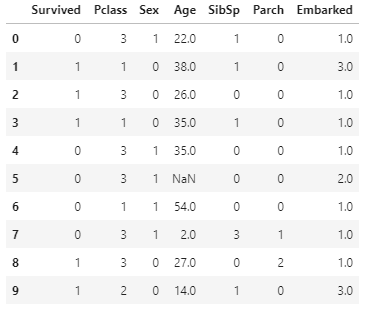
그다음 생각한 건 결측치를 확인하는 것이었습니다.
우선 결측치 정보를 불러오기 위해서 isnull을 사용하였습니다.
df.isnull().sum()나이에서 177개의 결측치가 발생하였습니다.
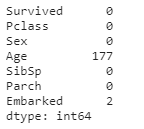
이 부분에서 결측치를 채우기 위해서 저는 조건을 부여한 그룹에서 표본을 추출하여 동일 그룹에 적용하는 방법을 사용하려고 생각했습니다. 뒤에 나오겠지만 여기서 제가 잘못 생각하게 됩니다.
우선은 우선 Age를 Float 타입으로 변경해주고
age_test라고 하는 신규 테이블을 만들었습니다.
그리고 fillna를 이용해서 NaN 값을 0으로 변환했습니다.
df = df.astype({'Age':'float'})
df['age_test'] = df['Age']
df.Age = df.Age.fillna(0)
df.age_test = df.age_test.fillna(0)
df.head
결측치를 채워주기 위해서 사전 작업은 모두 끝냈습니다.
제가 생각한 결측치를 채워주는 방법을 먼저 설명드리겠습니다.

위의 그림처럼 Sex, Pclass, SibSp, Parch를 모두 동일한 조건을 주고 Age가 위에서 0으로 바꿔준, 결측치가 없는 테이블을 신규로 re_age로 만들어줬습니다. 그리고 그 테이블에서 랜덤으로 추출한 값을 결측치에 채워주는 것으로 생각했습니다.
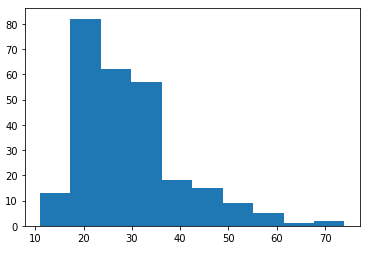
이를 위해 우선 위에서 말한 조건에 맞는 re_age 테이블을 신규로 만들고 그 테이블의 히스토그램을 확인했습니다.
import matplotlib.pyplot as plt
re_age = df[(df.Pclass == 3) & (df.SibSp == 0) & (df.Parch == 0) & (df.Sex == 1) & (df.Age != 0)]
plt.hist(re_age.Age)
plt.show() #현재 3등실의 가족 없는 남자의 연령별 히스토그램확실히 가족이 없는 젊은 남자가 조건이다 보니 20~30대에 높은 비중을 가지고 있는 것으로 보입니다.

여기서 실수한 부분이 바로 re_age 테이블에서 데이터를 추출하는 방식을 100번 반복하도록 한 것입니다.
히스토그램 상 20~30대의 연령이 높게 나오는 상황에서 이를 100번 반복하게 되면 데이터 값이 평균 회귀하면서 자연스럽게 가장 중간값이 올라갈 것임을 생각하지 못하고
100번을 반복하게 되면 전체 값이 고르게 올라갈 것이라는 착각을 했습니다.
이를 위해 For 구문을 만들고 랜덤 데이터 추출 함수를 짜는 동안 매우 큰 작업 로스가 발생했습니다.
결과적으로 나온 값은 사용하지 못하고 폐기해야 했습니다.
그래도 고민의 결과였다고 생각하고 같은 실수를 반복하지 않기 위해 해당 작업 내용도 같이 올리도록 하겠습니다.
for k in range(1,100) :
for i, row in df.iterrows() :
if df.at[i,'Pclass'] == 3 and df.at[i,'Sex'] == 1 and df.at[i,'SibSp'] == 0 and df.at[i,'Parch'] == 0 and df.at[i,'Age'] == 0 :
df.at[i,'age_test'] = df.at[i,'age_test'] + re_age.Age.iloc[np.random.randint(1,len(re_age.Age))]
for i, row in df.iterrows() :
if df.at[i,'Pclass'] == 3 and df.at[i,'Sex'] == 1 and df.at[i,'SibSp'] == 0 and df.at[i,'Parch'] == 0 and df.at[i,'Age'] == 0 :
df.at[i,'Age'] = (df.at[i,'age_test'] / 100)
plt.hist(df[(df.Pclass == 3) & (df.SibSp == 0) & (df.Parch == 0) & (df.Sex == 1)].Age)
plt.show() #Age가 누락된 인원들의 데이터를 표본추출로 대입한 후의 히스토그램
결과적으로 위에서 설명드린 평균 회귀로 인해 20~30대 사이의 값이 매우 높게 올라가는 현상이 발생했습니다.

결과적으로 결측치를 채우는 방법이 잘못되었음을 확인하고 이를 1회만 반영하는 방법으로 다시 반영하였습니다.
for i, row in df.iterrows() :
if df.at[i,'Pclass'] == 3 and df.at[i,'Sex'] == 1 and df.at[i,'SibSp'] == 0 and df.at[i,'Parch'] == 0 and df.at[i,'Age'] == 0 :
df.at[i,'Age'] = re_age.Age.iloc[np.random.randint(1,len(re_age.Age))]
plt.hist(df[(df.Pclass == 3) & (df.SibSp == 0) & (df.Parch == 0) & (df.Sex == 1)].Age)
plt.show() #Age가 누락된 인원들의 데이터를 표본추출로 대입한 후의 히스토그램최초 히스토그램과 유사한 히스토그램이 만들어졌습니다.
결과적으로 이 방식으로 모든 항목에 대한 결측치를 채워준 뒤 다른 분석 방법을 사용해봐야 할 것 같습니다.
같은 실수를 반복하지 않는 것이 중요하다고 생각합니다.
'데이터 분석 > 파이썬' 카테고리의 다른 글
| [Kaggle/캐글]PUBG 승률예측_1 (0) | 2021.05.31 |
|---|---|
| [Kaggle/캐글]타이타닉 생존률 분석_2 (0) | 2021.05.25 |
| [Kaggle/캐글]롤(lol) 챌린저 리그 오브젝트 영향 분석_1 (2) | 2021.05.18 |